
الگوریتم های جستجوی رشته ( و یا تطبیق رشته ها ) به رده ی مهمی از الگوریتم های موجود در رابطه با رشته ها اطلاق می شود. در این گونه از الگوریتم ها، مسئله ی اصلی پیدا کردن مکان های تکرار یک یا چند الگوی مورد جستجو ( Pattern ) در یک رشته ی بزرگ ( Text ) است.
در این مثال، رشته ها از کنار هم گذاشتن تعدادی کاراکتر متعلق به یک مجموعه ی متناهی به نام الفبا ( Σ ) ساخته می شوند. Σ می تواند حروف الفبای معمولی ( از A تا Z ) ، الفبای دودویی ( { 0 , 1 } ) یا الفبای DNA ( { A , C , G , T } ) باشد که بسته به محل و کاربرد مسئله، تعیین می شود.
در هر حالت از محیط اجرای الگوریتم و شرایط مسئله، باید این شرایط را به خوبی بررسی کرد و بهترین الگوریتم را برای پیاده سازی و استفاده برگزید. به عنوان مثال، ممکن است حالات زیر بر محیط مسئله حاکم باشد:
• طول رشته Text بلند و طول رشته های Pattern بسیار کوتاه باشد.
• طول رشته Text بلند و طول رشته های Pattern نیز بلند باشد.
• رشته های Pattern ثابت باشند و تکرار های آن ها در رشته های Text متفاوت به صورت مداوم پرسمان شود.
• رشته ی Text ثابت باشد و Pattern های مختلف در طول زمان پرسمان شوند.
برای گرفتن بهترین کارایی در هر یک از این شرایط، باید الگوریتم مشخصی را انتخاب کرد.
همچنین در نوعی از این مسئله، رشته های Pattern به صورت یک عبارت منظم داده می شوند، و باید جایگاه تمام زیررشته هایی که با آن عبارت منظم مطابق هستند به عنوان خروجی برگردانده شود.
الگوریتم های جستجوی رشته به صورت کلی به سه دسته ی زیر تقسیم می شوند:
در جدول زیر، چند الگوریتم معروف ذکر شده و از نظر مرتبه ی زمانی و حافظه با هم مقایسه شده اند. ( m طول الگو ( Pattern ) ، n طول رشته متن ( Text ) و k = | Σ | برابر با تعداد حروف الفبا است )
• الگوریتم آهو - کوراسیک ( تعمیم یافته ی الگوریتم KMP )
• الگوریتم تطابق رشته Commentz - Walter ( تعمیم یافته ی الگوریتم Boyer - Moore )
• الگوریتم رابین کارپ برای جست وجوی چندالگویی
در این نوع از الگوریتم ها، استراتژی ها و ایده های متنوعی برای تطابق الگوهای ورودی ( که به شکل عبارت منظم یا زبان منظم داده می شوند ) به کار گرفته می شود.
آسان ترین و ناکارآمدترین راه برای آن که یک رشته و مکان آن را در یک متن پیدا کنیم، امتحان کردن یک به یک همه ی مکان هایی که آن رشته می تواند قرار بگیرد است. یعنی یک اشاره گر را به عنوان ابتدای الگو، روی متن جلو می بریم و بررسی می کنیم که آیا این اشاره گر، می تواند ابتدای یک تکرار از الگو در متن باشد یا خیر. برای این کار، کاراکترهای بعد از اشاره گر را دانه به دانه با الگو مقایسه می کنیم؛ در صورت عدم انطباق یکی از آن کاراکتر ها، مشخص می شود که اشاره گر در مکان فعلی نمی تواند نمایان گر یک تکرار برای رشته باشد، پس اشاره گر را یک واحد به جلو می بریم. و در صورتی تا انتهای مقایسه، هیچ تناقضی وجود نداشت، به این معنی است که اشاره گر به یک تکرار از الگو در متن اشاره می کند. [ ۱]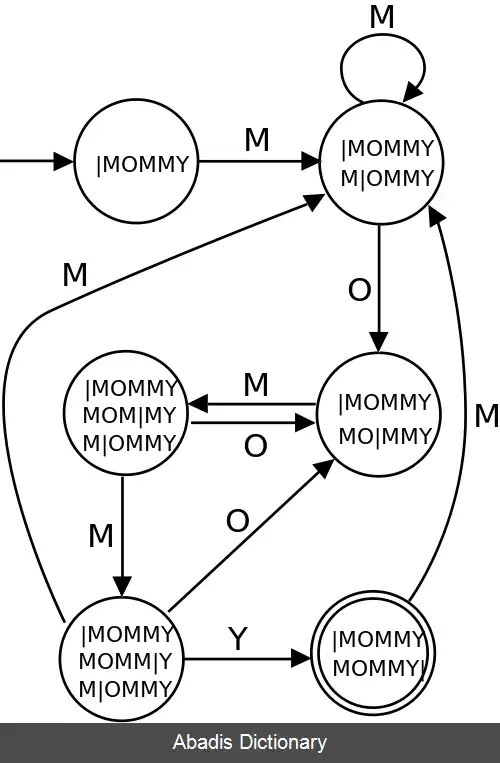
این نوشته برگرفته از سایت ویکی پدیا می باشد، اگر نادرست یا توهین آمیز است، لطفا گزارش دهید: گزارش تخلفدر این مثال، رشته ها از کنار هم گذاشتن تعدادی کاراکتر متعلق به یک مجموعه ی متناهی به نام الفبا ( Σ ) ساخته می شوند. Σ می تواند حروف الفبای معمولی ( از A تا Z ) ، الفبای دودویی ( { 0 , 1 } ) یا الفبای DNA ( { A , C , G , T } ) باشد که بسته به محل و کاربرد مسئله، تعیین می شود.
در هر حالت از محیط اجرای الگوریتم و شرایط مسئله، باید این شرایط را به خوبی بررسی کرد و بهترین الگوریتم را برای پیاده سازی و استفاده برگزید. به عنوان مثال، ممکن است حالات زیر بر محیط مسئله حاکم باشد:
• طول رشته Text بلند و طول رشته های Pattern بسیار کوتاه باشد.
• طول رشته Text بلند و طول رشته های Pattern نیز بلند باشد.
• رشته های Pattern ثابت باشند و تکرار های آن ها در رشته های Text متفاوت به صورت مداوم پرسمان شود.
• رشته ی Text ثابت باشد و Pattern های مختلف در طول زمان پرسمان شوند.
برای گرفتن بهترین کارایی در هر یک از این شرایط، باید الگوریتم مشخصی را انتخاب کرد.
همچنین در نوعی از این مسئله، رشته های Pattern به صورت یک عبارت منظم داده می شوند، و باید جایگاه تمام زیررشته هایی که با آن عبارت منظم مطابق هستند به عنوان خروجی برگردانده شود.
الگوریتم های جستجوی رشته به صورت کلی به سه دسته ی زیر تقسیم می شوند:
در جدول زیر، چند الگوریتم معروف ذکر شده و از نظر مرتبه ی زمانی و حافظه با هم مقایسه شده اند. ( m طول الگو ( Pattern ) ، n طول رشته متن ( Text ) و k = | Σ | برابر با تعداد حروف الفبا است )
• الگوریتم آهو - کوراسیک ( تعمیم یافته ی الگوریتم KMP )
• الگوریتم تطابق رشته Commentz - Walter ( تعمیم یافته ی الگوریتم Boyer - Moore )
• الگوریتم رابین کارپ برای جست وجوی چندالگویی
در این نوع از الگوریتم ها، استراتژی ها و ایده های متنوعی برای تطابق الگوهای ورودی ( که به شکل عبارت منظم یا زبان منظم داده می شوند ) به کار گرفته می شود.
آسان ترین و ناکارآمدترین راه برای آن که یک رشته و مکان آن را در یک متن پیدا کنیم، امتحان کردن یک به یک همه ی مکان هایی که آن رشته می تواند قرار بگیرد است. یعنی یک اشاره گر را به عنوان ابتدای الگو، روی متن جلو می بریم و بررسی می کنیم که آیا این اشاره گر، می تواند ابتدای یک تکرار از الگو در متن باشد یا خیر. برای این کار، کاراکترهای بعد از اشاره گر را دانه به دانه با الگو مقایسه می کنیم؛ در صورت عدم انطباق یکی از آن کاراکتر ها، مشخص می شود که اشاره گر در مکان فعلی نمی تواند نمایان گر یک تکرار برای رشته باشد، پس اشاره گر را یک واحد به جلو می بریم. و در صورتی تا انتهای مقایسه، هیچ تناقضی وجود نداشت، به این معنی است که اشاره گر به یک تکرار از الگو در متن اشاره می کند. [ ۱]

wiki: الگوریتم جستجوی رشته